
Indice
Prosegue senza sosta il lavoro di ricerca per migliorare il rilevamento e la classificazione delle avversità che colpiscono le piante. Protagonista, questa volta, è il susino, un albero da frutto tropicale di grande importanza per l’agricoltura e l’industria alimentare. Diverse sono, però, le avversità – soprattutto a livello fogliare – che possono compromettere significativamente resa e qualità del raccolto. Nonostante i progressi ottenuti nella diagnosi precoce di molte colture, il susino ha dovuto attendere il suo momento, che finalmente è arrivato. Un team di ricercatori in Bangladesh ha infatti sviluppato un innovativo set di dati, progettato per addestrare e testare algoritmi di intelligenza artificiale dedicati a questa pianta.
Un dataset che rappresenta un punto di riferimento essenziale per i sistemi di visione artificiale e apprendimento automatico, consentendo di distinguere con precisione tra foglie sane e malate. Grazie a questo strumento sarà, infatti, possibile intervenire tempestivamente per la gestione della salute delle piante, promuovendo un’agricoltura più sostenibile ed efficiente.
- Leggi anche: Susino sangue di drago: gemma tra le varietà
Come è stato costruito il nuovo dataset per il susino?
Per realizzare il nuovo dataset dedicato al susino, i ricercatori hanno raccolto 3.782 immagini tra giugno e ottobre 2024 in diverse aree del Bangladesh, selezionate per rappresentare un’ampia varietà di condizioni ambientali e di coltivazione. Le fotografie ritraggono sia foglie sane sia foglie danneggiate da insetti, in differenti stadi di sviluppo. Prima di essere utilizzate nei modelli di intelligenza artificiale, le immagini sono state ottimizzate: ridimensionate a 800×800 pixel, normalizzate nei valori dei pixel e sottoposte a un’attenta pulizia per rimuovere duplicati e scatti di scarsa qualità.
Il processo di etichettatura è stato affidato a un agronomo esperto, che ha garantito la corretta classificazione di ogni immagine come “sana” o “malata”, assicurando così l’accuratezza e la solidità scientifica del dataset.
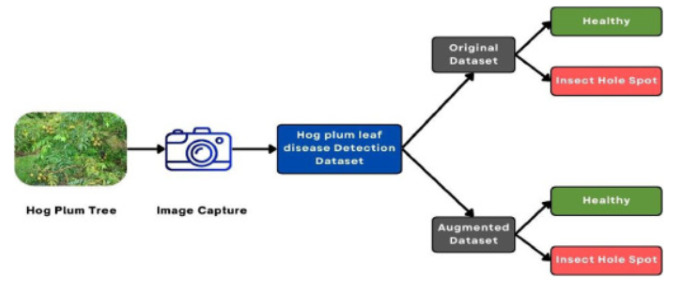
Organizzazione del set di dati sulla malattia delle foglie di susino
Tecniche di data augmentation per un dataset più robusto
Per rendere il dataset più completo e adattabile a scenari reali, i ricercatori hanno applicato una serie di trasformazioni alle immagini originali, tra cui rotazione, capovolgimento, ritaglio, zoom e modifiche a luminosità e contrasto. È stato anche aggiunto del rumore visivo, simulando così diverse condizioni di luce e angolazione. Grazie a queste tecniche di data augmentation, il numero complessivo di immagini è salito, da 3.782 a circa 20.000, aumentando in modo significativo la capacità dei modelli di riconoscere le avversità in contesti variabili.
Il dataset è stato poi suddiviso in due parti: l’80% delle immagini è stato utilizzato per l’addestramento degli algoritmi, mentre il restante 20% è servito per la fase di verifica. Durante i test, i ricercatori hanno messo alla prova diversi modelli di deep learning tra i più avanzati, come VGG16, ResNet e Inception. L’addestramento si è svolto in 30 cicli, con un sistema intelligente di regolazione automatica della velocità di apprendimento, utile per evitare problemi di overfitting.
Luci e ombre del database
Uno degli aspetti più rilevanti del progetto è la struttura ordinata e funzionale del database, pensata per semplificare il lavoro degli sviluppatori. Le immagini raccolte sono infatti organizzate in due grandi sezioni: l’Original Dataset, che contiene le fotografie naturali suddivise tra foglie sane (Healthy) e malate (Not_Healthy), e l’Augmented Dataset, che include le versioni modificate delle stesse immagini, mantenendo la medesima classificazione. Questa impostazione rende il dataset uno strumento immediatamente utilizzabile per l’addestramento e la valutazione dei modelli di intelligenza artificiale, facilitando lo sviluppo di soluzioni efficaci.
Nonostante i risultati incoraggianti, il progetto presenta alcune criticità. Le immagini provengono esclusivamente dal Bangladesh, il che potrebbe compromettere l’efficacia dei modelli se applicati in contesti geografici o ambientali differenti. Inoltre, la qualità delle immagini – variabile a causa delle diverse condizioni di luce e ambiente durante la raccolta – può influire sulla precisione dei modelli in applicazioni reali. Ciononostante, queste limitazioni non vanno viste come un ostacolo bensì come un’opportunità per perfezionare ulteriormente gli strumenti automatizzati di monitoraggio e supporto decisionale in ambito agricolo. Ne sono ben consapevoli i ricercatori, certi che, in un futuro non così lontano, queste tecnologie potranno diventare alleate preziose per gli agricoltori, aiutandoli a gestire in modo più efficiente le colture, incrementando la produttività e favorendo pratiche agricole sempre più sostenibili.
- Leggi anche: Sharka: contrastarla con la genetica
Federica Del Vecchio
© fruitjournal.com