
Indice
Peronospora, muffa fogliare, septoriosi fogliare: per gli agricoltori, questi nomi non sono certo una novità. Sono alcune fra le principali avversità del pomodoro che, se non identificate e trattate tempestivamente, possono compromettere gravemente qualità e quantità del raccolto, con pesanti conseguenze economiche. Tradizionalmente, la diagnosi si affida all’esperienza di agronomi e tecnici, capaci di riconoscere i primi segnali a occhio nudo. Ma si tratta di un processo lungo, soggetto a errori e sempre meno compatibile con un’agricoltura che punta sull’efficienza, la sostenibilità e la velocità di intervento. Ed è proprio in questo scenario che la tecnologia può fare la differenza. Un team di ricercatori dell’Università di Tarim (Cina) ha, infatti, messo a punto una nuova versione dell’algoritmo YOLO – già noto per le sue applicazioni nel riconoscimento automatico di immagini in ambito agricolo – adattandolo alle specifiche esigenze della diagnosi sulle foglie di pomodoro. Il risultato è un modello potenziato, ribattezzato BED-YOLO, capace di identificare in modo ancora più preciso e veloce le avversità che possono colpire le colture. Ma come funziona esattamente?
- Leggi anche: Pomodoro italiano e DNA: nuove varianti genetiche
Avversità del pomodoro: l’AI arriva dove l’occhio umano si ferma
BED-YOLO è un modello avanzato di intelligenza artificiale sviluppato a partire dalla versione esistente YOLOv10n, uno degli algoritmi più rapidi e precisi per il riconoscimento visivo. L’obiettivo? Rilevare le malattie dalle foglie di pomodoro anche nelle condizioni più complesse: illuminazione irregolare, foglie sovrapposte, sfondi caotici. Per raggiungere questo risultato, il team ha introdotto tre innovazioni chiave che rendono il sistema più preciso, stabile e adattabile. Il primo miglioramento riguarda l’impiego delle convoluzioni deformabili (DCN), una tecnologia che consente al modello di adattarsi meglio alle forme irregolari delle lesioni, spesso sfumate o parzialmente nascoste. A questo si aggiunge l’integrazione del BiFPN (Bidirectional Feature Pyramid Network), un meccanismo che migliora la capacità dell’algoritmo di leggere informazioni a diverse scale di grandezza, fondamentale per riconoscere anche le lesioni più piccole.
Infine, è stato implementato il meccanismo EMA (Exponential Moving Average), che riduce i “disturbi” visivi e garantisce maggiore coerenza e stabilità durante l’analisi delle immagini. Il risultato è un modello più potente e affidabile, in grado di supportare con efficacia la diagnosi precoce nei campi coltivati.
Un archivio visivo contro le avversità del pomodoro
Per costruire un sistema davvero efficace, serve una base solida: nel caso dell’intelligenza artificiale, questa base è rappresentata dai dati. E così, per allenare il modello BED-YOLO, i ricercatori hanno raccolto e costruito un vasto archivio di immagini di foglie di pomodoro malate. La maggior parte delle fotografie – 1.218 immagini – è stata scattata direttamente sul campo, in una piantagione di pomodori a Wujiaqu, nello Xinjiang, con l’aiuto di esperti fitopatologi. Le foto sono state realizzate in diversi momenti della giornata – mattina, mezzogiorno, sera – per includere variazioni di luce naturali, rendendo il dataset più realistico e rappresentativo. Le foglie ritratte mostravano diversi stadi della malattia, da quello iniziale a quello avanzato, e includevano sfondi naturali come terra, erba e vegetazione, simulando così le reali condizioni di un campo agricolo.
A questa raccolta sul campo, i ricercatori hanno affiancato il contributo del dataset pubblico PlantVillage, uno strumento di riferimento per la classificazione delle malattie delle piante. Circa il 35% delle immagini (656 su 1874 in totale) proviene proprio da questa banca dati. Tutte le immagini sono state bilanciate e pre-elaborate, in modo da garantire una distribuzione equa delle avversità analizzate, migliorando così l’efficacia dell’apprendimento. Le immagini sono poi state suddivise casualmente: l’80% è stato utilizzato per addestrare il modello, il 20% per testarlo.
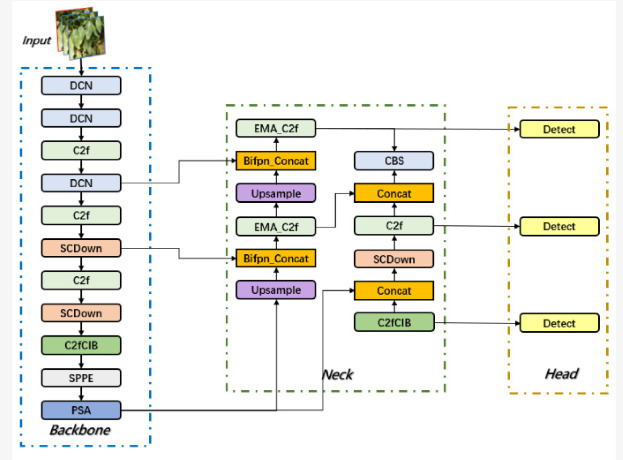
Architettura di rete BED-YOLO.
BED-YOLO: il nuovo alleato digitale contro le avversità del pomodoro
Per indicare con precisione le aree colpite da ogni avversità, gli esperti hanno utilizzato LabelImg, un software che consente di tracciare riquadri attorno alle lesioni e assegnare a ciascuna un’etichetta. Ma non è finita qui: per rendere il modello ancora più robusto e versatile, i ricercatori hanno “moltiplicato” artificialmente le immagini attraverso tecniche di data augmentation. Hanno quindi introdotto modifiche come rotazioni, cambi di luminosità, tagli casuali e disturbi visivi, simulando condizioni ambientali variabili. Il risultato? Un dataset più ricco e realistico, capace di preparare il modello a funzionare efficacemente anche in contesti complessi e reali, come quelli che ogni giorno si trovano ad affrontare gli agricoltori.
I risultati sperimentali parlano chiaro: BED-YOLO ha superato algoritmi consolidati come YOLOv5n, YOLOv8n e Faster R-CNN per precisione, capacità di individuazione (recall) e mAP, dimostrandosi particolarmente efficace nel rilevare alcune delle principali avversità del pomodoro. Rispetto al modello originario infatti, BED-YOLO ha evidenziato una maggiore capacità di identificare con chiarezza le lesioni, mostrando livelli più alti di fiducia nelle diagnosi e una maggiore stabilità operativa.
Le prossime sfide
Nonostante le prestazioni promettenti, la strada verso un’applicazione diffusa nei campi agricoli richiede ulteriori sforzi. Il contesto produttivo in continua evoluzione determina sempre più frequentemente l’introduzione di nuove malattie e varietà di pomodoro, richiedendo modelli sempre più adattabili e generalizzabili. Allo stesso tempo, la disponibilità di dataset agricoli ampi e ben etichettati rimane un limite: raccogliere immagini e annotarle con precisione è costoso e richiede tempo.
La sfida è quindi duplice: da un lato, evitare il rischio di sovra-allenamento su pochi dati; dall’altro, garantire prestazioni elevate anche su dispositivi leggeri come droni, smartphone o sensori da campo. In questo contesto, i prossimi obiettivi della ricerca si concentrano sull’uso del transfer learning, dell’apprendimento debolmente supervisionato e sull’integrazione di dati multi-sorgente – dalle immagini alle informazioni climatiche – per costruire un modello sempre più efficiente, flessibile e realmente utile per un’agricoltura intelligente, sostenibile e tecnologicamente avanzata.
- Leggi anche: Concimazione del pomodoro: fisologia e fabbisogno
Federica Del Vecchio
© fruitjournal.com